La inteligencia artificial está transformando radicalmente nuestra interacción con la información. Si bien su potencial de productividad es enorme, introduce un cambio crítico en materia de seguridad para el que muchas organizaciones no están preparadas. En este artículo, nos centraremos en los desafíos específicos que surgen cuando las empresas implementan agentes de IA para fines comerciales internos y por qué nuestros modelos de seguridad tradicionales ya no son suficientes.
El Fin de la Lógica
del Middleware
Tradicionalmente, utilizábamos aplicaciones para procesar y recuperar datos. Estas aplicaciones codificaban toda la lógica de negocio e imponían la seguridad. Actuaban como «canales rígidos»: guardianes con código fijo que solo permitían consultas específicas, seguían una lógica específica y devolvían resultados deterministas y predecibles.
Con la aparición de la IA y el procesamiento del lenguaje natural (PLN), avanzamos hacia una interacción de datos «sin aplicaciones». Los usuarios ahora pueden comunicarse con una IA autorizada para acceder a los datos en su nombre. La IA es la nueva aplicación. Formatea dinámicamente las consultas SQL, determina qué llamadas a la API realizar, procesa la información y genera una respuesta a la pregunta. La capa de aplicación ahora es un LLM con agentes y conectores que vinculan el cerebro de la IA con los datos, pero no aplica ni lógica de negocio ni controles de seguridad.
Esto crea un enorme vacío de seguridad. Anteriormente, dependíamos de la capa de aplicación para aplicar las reglas de seguridad y la lógica de negocio. Ahora, la «aplicación» no cumple con este requisito. La IA es un generador dinámico de consultas, y cuanto más datos puede acceder, más peligrosa se vuelve. Puede cruzar información y llegar a conclusiones con una velocidad y escala que ningún humano podría igualar.
Por Qué No Se Puede «Arreglar» la IA
Ante este problema, muchos intentan «proteger» la propia IA. Esto es un error por dos razones principales:
1. El Problema del Entrenamiento
La idea de que podemos «enseñar» a una IA a no revelar información confidencial es una falacia comprobada. Si bien se pueden proporcionar instrucciones al sistema, estas son notoriamente ineficaces. Mediante técnicas como la inyección de mensajes y el jailbreaking, los usuarios pueden eludir los protocolos de seguridad creando una sensación de urgencia, pidiendo a la IA que simule un juego de rol o simplemente inventando una necesidad ficticia. La seguridad impuesta por la IA no es determinista y tiene un número infinito de posibles entradas y salidas. Esto significa que no se puede comprobar de forma fiable si el entrenamiento fue efectivo y nunca se debe confiar en él para proteger información confidencial.
2. El Problema de la Ofuscación de Datos
Algunos sugieren «limpiar» los datos a medida que entran o salen de la IA. Sin embargo, un usuario ingenioso puede pedirle a la IA que ofusque los datos. Puede indicarle que convierta dígitos a letras usando una clave personalizada o que devuelva los datos codificados en Base64. Cuando la IA escribe el SQL por sí misma, estas transformaciones pueden ocurrir a nivel de base de datos. Si no lo hace, las transformaciones ocurren en la propia IA. En cualquier caso, hacen que los filtros de salida tradicionales sean ineficaces e incapaces de detectar la fuga de datos.
Estrategia de Defensa Multicapa
Dado que no podemos proteger el «cerebro de la IA», debemos proteger los datos en su origen. Debemos pasar de un paradigma de seguridad centrado en la aplicación a un modelo centrado en la base de datos.
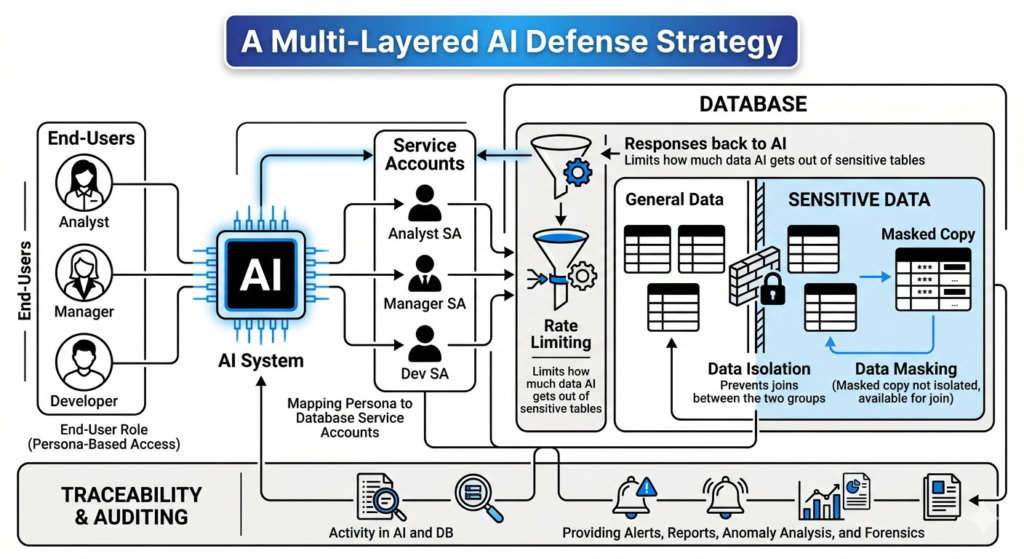
Rol de Usuario Final (Acceso Basado en la Persona)
La IA no debería usar un usuario de base de datos con acceso ilimitado, como lo hacía la aplicación. En su lugar, la IA debería conectarse mediante Cuentas de Servicio Basadas en Roles. Con estas cuentas, el equipo de Marketing que utiliza la IA no tendría acceso a información confidencial. La información de identificación personal (PII) debería bloquearse o enmascararse dinámicamente a nivel de base de datos. Esta asignación de usuarios a roles siempre la ha realizado la aplicación, pero ahora debe ser aplicada por la base de datos. Si bien esta medida por sí sola no impedirá que un usuario deduzca información (como identificar a un director ejecutivo por su salario más alto), garantiza que la IA no pueda acceder a información que el usuario no tiene permitido ver ni modificar información confidencial.
Limitación de Velocidad
Para evitar la filtración masiva de datos, debe establecer límites estrictos en el volumen de datos confidenciales que una IA puede consultar. Por ejemplo, un máximo de 100 filas por minuto de tablas confidenciales. Para evitar alcanzar este límite, se debe configurar la IA para que agregue los datos confidenciales en la base de datos en lugar de volcar todas las filas. Sin embargo, la base de datos debe imponer un límite estricto en el número de filas devueltas, garantizando que la seguridad no pueda eludirse mediante una solicitud ingeniosa.
Aislamiento de Datos
Los datos confidenciales deben estar aislados dentro del esquema. Debe impedir que la IA combine tablas de información personal identificable (PII) confidenciales con datos de actividad general en una sola consulta. Esto restringe su capacidad para extraer información confidencial y correlacionarla. El acceso a la PII debe ser un segundo paso deliberado, controlado por la base de datos, y no una parte incidental de una consulta analítica amplia. Para combinar con características de usuario específicas que existen en la PII, utilice datos enmascarados (véase más abajo).
Enmascaramiento de Datos (Ruido Publicado)
El aislamiento de datos a veces puede limitar la utilidad de la IA (por ejemplo, no puede explicar por qué los clientes de Nueva York cancelan si no tiene acceso a los datos de ubicación). La solución consiste en añadir una copia enmascarada de la información confidencial con ruido integrado que preserva la privacidad. Esto es mucho más sencillo que la privacidad diferencial y evita el ruido laplaciano ilimitado. Al proporcionar a la IA estos datos alternativos, puede realizar análisis «seguros» de tendencias sin exponerse a los valores confidenciales reales que se ocultan mediante el aislamiento de datos o los permisos basados en perfiles de usuario.
Trazabilidad y Auditoría
Las medidas de detección son la mejor protección contra el abuso interno. Debe poder correlacionar cada respuesta de la IA con el usuario final específico que la generó.
- Nivel de Base de Datos: registros de auditoría de la base de datos enriquecidos con información del usuario final transmitida por el agente de IA. El agente debe etiquetar la sesión o las consultas SQL (en caso de agrupación de sesiones), y la solución de auditoría de la base de datos debe estar programada para identificar dichas etiquetas. El etiquetado debe realizarse en función de las capacidades de su solución de auditoría de bases de datos.
- Nivel de Aplicación: Implemente un registro robusto que capture la solicitud, las consultas generadas, el número de filas procesadas y la respuesta.
En cualquier caso, es fundamental contar con informes, alertas, análisis y análisis forense potentes para garantizar que sepa quién accede a los datos confidenciales, cuándo y cuánto.
Conclusión
La transición a un mundo impulsado por la IA implica muchos cambios, incluyendo la forma en que protegemos nuestros datos. El camino a seguir es volver a los fundamentos que abandonamos cuando la aplicación nos prometió seguridad. Ya no podemos confiar en la «capa intermedia» para protegernos ni en la «inteligencia» de la IA para mantener nuestros secretos.
Si está creando o implementando agentes de IA, deje de intentar proteger la solicitud y comience a proteger el esquema de datos:
- Migre sus conexiones de IA a cuentas de servicio basadas en perfiles de usuario.
- Utilice soluciones avanzadas de seguridad de bases de datos para cubrir las deficiencias de la seguridad integrada de su base de datos (como la limitación de velocidad, el bloqueo de uniones, la trazabilidad, etc.).
- Aproveche las soluciones avanzadas de enmascaramiento de datos para proporcionar datos enmascarados que preserven la privacidad.
En la era de la IA, su base de datos es su único perímetro de seguridad.
- Introducción
- El Fin de la Lógica del Middleware
- Por Qué No Se Puede «Arreglar» la IA
- Estrategia de Defensa Multicapa
- Conclusión
Registrate al Webinar
Para saber más haz click aquí
Sugerencia de IA


¿Preguntas?
Si tenes alguna pregunta o comentario, no dude en hacérnoslo saber. Estaremos encantados de escucharles