Analicemos algunas variantes del enmascaramiento dinámico de datos (DDM) y expliquemos las diferencias con su contraparte estática. Cubriremos diferentes enfoques de implementación, en qué situaciones se aplican y las alternativas preferidas.
Estático vs. Dinámico: «Permanente» o «En Tiempo Real»
Antes de profundizar en la implementación técnica, debemos distinguir entre las dos filosofías principales del enmascaramiento: estático y dinámico.
Enmascaramiento de Datos Estáticos (SDM)
El enmascaramiento estático se puede considerar como una «renovación permanente». En este proceso, modificamos físicamente los datos almacenados en la base de datos. Los valores confidenciales originales se sobrescriben con datos ficticios, aunque realistas.
- Cómo funciona: Utiliza operaciones de actualización para anonimizar los datos.
- Cuándo usarlo: Es el método estándar para entornos que no son de producción (desarrollo, pruebas, análisis). Es más sencillo, económico y seguro que cualquier otro método. Una vez enmascarada, la base de datos es inherentemente segura, lo que significa que no se necesitan protocolos de seguridad complejos, ya que los datos reales simplemente ya no están presentes.
- Cuándo NO usarlo: Cuando se necesitan los datos, no se pueden eliminar. Por lo tanto, el enmascaramiento estático no es apropiado para bases de datos de producción. Una excepción poco común es cuando los datos enmascarados se utilizan específicamente para actividades de producción. Por ejemplo, para informes públicos, acceso de terceros, etc.
Enmascaramiento Dinámico de Datos (DDM)
El enmascaramiento dinámico es una técnica que utiliza la técnica del «sombrero y espejos». Los datos reales permanecen intactos en la base de datos, pero se enmascaran al enviarlos a algunos usuarios.
- Cómo funciona: Intercepta la consulta SQL y la reescribe sobre la marcha.
- Cuándo usarlo: Está diseñado para entornos de producción donde los datos deben permanecer originales para que el sistema funcione, pero ciertos usuarios solo deben ver una versión censurada.
- Cuándo NO usarlo: Si bien se podría usar el enmascaramiento dinámico en entornos que no sean de producción, su costo y complejidad lo hacen inapropiado. Además, una base de datos con enmascaramiento dinámico aún contiene información confidencial y debe estar totalmente protegida. Esto aumenta aún más los costos y la complejidad. El enmascaramiento estático es el enfoque preferido en esos casos.
Cómo Funciona:
El Arte de la Reescritura SQL
El enmascaramiento dinámico es esencialmente un proceso de traducción. Cuando un usuario solicita datos, el motor de enmascaramiento intercepta la solicitud y modifica la sentencia SQL. Existen dos métodos principales para lograrlo:
Reescritura de Columnas
Este método reemplaza la columna solicitada con una función de enmascaramiento.
- Original: SELECT col1 FROM table1
- Enmascarado: SELECT mask_func(col1) FROM table1
- El desafío: El análisis sintáctico de SQL es técnicamente complejo en general y aún más, ya que depende de los metadatos de la base de datos. Algunos ejemplos:
- Las sentencias «SELECT*» son complejas porque el nombre de la columna no aparece y el asterisco (*) debe reemplazarse por la lista actual de columnas (lo que requiere metadatos de la base de datos).
- Los alias de columnas y tablas son complejos porque sus nombres pueden aparecer de forma diferente en distintas partes de la consulta SQL. El alias también puede contener el nombre de la columna y no debe enmascararse.
- Las cláusulas WHERE también deben enmascararse para evitar fugas de datos, pero esto puede alterar la lógica SQL y afectar el rendimiento.
- En una unión (JOIN), los nombres de las columnas pueden referirse a cualquiera de las tablas. Pueden apuntar explícitamente a una tabla según su nombre (o alias) o referirse implícitamente a la tabla que las contiene (el análisis sintáctico depende de los metadatos de la base de datos).
- Entre los desafíos menores se incluyen el manejo de subconsultas o funciones de agregación, como SELECT SUM(col). Estos problemas suelen ser manejados fácilmente por los analizadores sintácticos.
Todos estos problemas pueden abordarse parcialmente, pero no con la misma perfección que la solución de vista de base de datos que se describe a continuación. Una vista aprovecha el analizador SQL de la base de datos para integrar el enmascaramiento en todas partes.
Vista Enmascarada
Este método consiste en crear una versión «oculta» de la tabla. Generalmente, utiliza una vista, pero también puede emplear una vista materializada o una tabla enmascarada estáticamente.
- Original: SELECT col1 FROM table1
- Emascarado: SELECT col1 FROM table1_masked
- El desafío: Esta solución es más segura y mucho más robusta en términos de reescritura de SQL. Sin embargo, puede ser fácilmente eludida por personal con acceso de alto nivel a la base de datos, como los administradores de bases de datos (DBA). Por ejemplo, no se puede enmascarar dinámicamente la actividad de un DBA mediante una vista, ya que un DBA puede examinar la tabla subyacente o modificar la vista para revelar la información real.
Otros Métodos
Vale la pena analizar un par de alternativas:
Reemplazo de datos: Algunas soluciones intentan reemplazar los datos devueltos por la consulta en lugar de reescribirla. Esto es extremadamente frágil y fácil de eludir, ya que los datos carecen de información contextual. Es imposible saber si 92000 es un salario, un código postal, un ID de cliente u otra cosa. Los nombres de las columnas devueltas se pueden modificar fácilmente, al igual que los datos (por ejemplo, mediante la función translate).
Proceso de desarrollo propio (DIY): Algunos abordan el problema como un desafío de programación de aplicaciones. Enmascarar los datos de una aplicación es similar a una funcionalidad o mejora. Sin embargo, estas mejoras no son posibles en aplicaciones comerciales o en aplicaciones que no están en desarrollo activo. Incluso para aplicaciones en desarrollo activo, puede ser una tarea monumental que se resuelve mejor con una solución de enmascaramiento dinámico.
La Ubicación Importa:
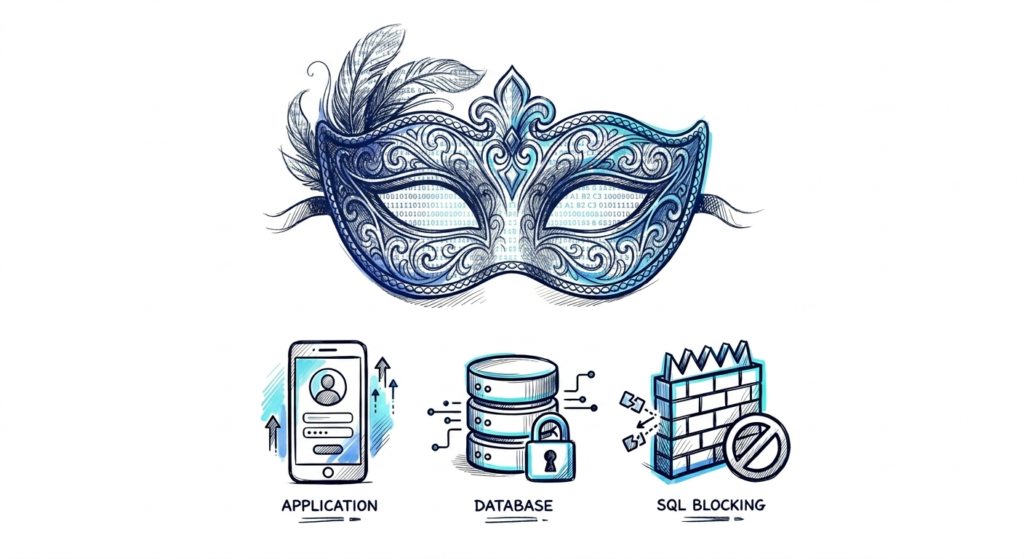
Lado de la App vs. BBDD
Una vez que decida usar el enmascaramiento dinámico, deberá decidir dónde ubicar el «cerebro del enmascaramiento».
Lado de la aplicación (Lado del cliente)
Esta suele ser la solución más robusta que satisface las necesidades del cliente. Herramientas como Core Audit para Java pueden integrarse en la aplicación Java en tiempo de ejecución y agregar la lógica de enmascaramiento dinámico necesaria al controlador de cliente JDBC.
La ventaja: La aplicación sabe quién es el usuario final. En los sistemas modernos, la aplicación y todos sus usuarios comparten un único usuario de base de datos. A menudo, también comparten las mismas conexiones a la base de datos (agrupación de sesiones). La base de datos no puede distinguir entre los diferentes usuarios finales, pero la aplicación sí puede hacerlo fácilmente. Al reescribir el SQL dentro de la aplicación, se puede aplicar un enmascaramiento dinámico basado en el usuario específico sin modificar ni una sola línea de código fuente.
Además, el enmascaramiento del lado de la aplicación es más seguro, ya que no interfiere con el funcionamiento de la base de datos ni con la forma en que esta presta servicios a otros usuarios.
Lado de la Base de Datos (lado del servidor)
Cuando se busca enmascarar datos enviados a diferentes usuarios de la base de datos o a múltiples aplicaciones, el enmascaramiento a nivel de base de datos es la solución adecuada. Soluciones como Core Audit for Databases se conectan al motor SQL de la base de datos en tiempo de ejecución y agregan la lógica de enmascaramiento a la base de datos. Algunos motores de bases de datos incluyen esta funcionalidad, aunque a menudo con limitaciones importantes.
Sin embargo, el enmascaramiento a nivel de base de datos tiene un punto ciego. Generalmente, no puede identificar al usuario final de la aplicación original, especialmente cuando se utiliza la agrupación de sesiones. Trata todo el tráfico proveniente de la aplicación como un único usuario y una única aplicación, lo que hace que una seguridad más granular sea prácticamente imposible.
Enmascaramiento Dinámico Vs. Bloqueo SQL
En ocasiones, el enmascaramiento no es la herramienta adecuada. Aquí es donde entra en juego el bloqueo SQL.
Tienes dos opciones para impedir que un administrador o analista acceda a datos confidenciales: modificar su consulta para mostrarles estrellas (enmascaramiento) o detener la consulta por completo (bloqueo).
Consejo de seguridad: Bloquear una consulta es intrínsecamente más seguro que enmascararla. Reescribir una consulta «peligrosa» en una «segura» es propenso a errores. Esto puede ser peligroso si quien envía la consulta puede modificarla hasta encontrar una variación que el motor de enmascaramiento no logra reescribir correctamente. Si una consulta no debería ejecutarse, bloquearla es una medida de seguridad definitiva e ineludible.
Consideraciones Adicionales
Fortaleza de la seguridad: Existe una gran diferencia entre estos dos tipos de requisitos:
- Enmascaramiento de consultas SQL de la aplicación codificadas directamente en el código, donde se puede probar la funcionalidad de enmascaramiento dinámico. En este caso, los requisitos de robustez y ausencia total de vulnerabilidades son menos críticos. El usuario no puede modificar las consultas SQL que envía, y el implementador puede garantizar que los datos de la aplicación estén correctamente enmascarados.
- Enmascaramiento de consultas SQL escritas por personas (como administradores de bases de datos o analistas) que pueden modificarlas para intentar eludir la seguridad. En este caso, los requisitos de seguridad absoluta son mucho más estrictos. Poder enmascarar la mayoría de los casos no es suficiente.
- Cuanto más se orientan los requisitos hacia la impenetrabilidad, mejor es pasar del enmascaramiento dinámico al bloqueo. En estos casos, también conviene auditar la actividad para corregir posibles debilidades que aún puedan existir.
Rendimiento: El enmascaramiento dinámico de datos presenta tres aspectos de rendimiento:
- La sobrecarga en aplicaciones o sesiones que no requieren enmascaramiento. Esto se aplica únicamente al enmascaramiento del lado de la base de datos (no del lado de la aplicación). Este impacto en el rendimiento debería ser mínimo e imperceptible.
- El impacto en las consultas SQL que no requieren enmascaramiento, pero sí en sesiones que podrían requerirlo. Esta sobrecarga debería ser extremadamente pequeña y representa la evaluación de cada consulta SQL con respecto a todas las reglas de enmascaramiento y bloqueo pertinentes.
- Velocidad de reescritura de SQL. Este es el retraso adicional que se produce al aplicar el enmascaramiento dinámico. Suele ser poco frecuente y pequeño en comparación con el tiempo de respuesta de la base de datos.
El enmascaramiento dinámico del lado de la aplicación suele escalar mejor porque se ejecuta en paralelo en cada uno de los servidores de la aplicación y se adapta a su tamaño. El enmascaramiento dinámico del lado de la base de datos depende de los recursos limitados del servidor de base de datos. Sin embargo, en casi todos los casos, ninguno de los dos representa un problema.
Administrabilidad: Si dispone de varios servidores de aplicaciones o de bases de datos que deben sincronizarse para seguir las mismas reglas de enmascaramiento, coordinarlos puede resultar complejo. La administración centralizada puede ser fundamental en estos casos.
En Resumen:
Tu Estrategia de 4 Pasos
Proteger tus datos no se trata de elegir una sola herramienta, sino de usar la herramienta adecuada para cada amenaza específica. Así es como puedes organizar tu defensa:
- Para entornos de desarrollo/pruebas: Utilice el enmascaramiento estático de datos. Proteja los datos reemplazándolos por completo tan pronto como salgan de producción.
- Para proteger la producción de los administradores de bases de datos (DBA): Utilice el bloqueo de SQL. Dado que los DBA tienen permisos de acceso total, los controles de acceso tradicionales no funcionarán. Bloquear las consultas no autorizadas es la mejor manera de mitigar las amenazas provenientes de estas cuentas.
- Para proteger la producción de los usuarios de la aplicación: Utilice el enmascaramiento dinámico del lado de la aplicación. Esto proporciona el contexto necesario para mostrar datos parciales (enmascarados) según el usuario final.
- Para usuarios generales de la base de datos: Para otros usuarios (sin privilegios ni acceso a la aplicación), utilice los permisos estándar de la base de datos (GRANT/REVOKE). Solo recurra al enmascaramiento o al bloqueo si estos controles granulares resultan insuficientes para sus necesidades.
Además de estas medidas preventivas, una postura de seguridad adecuada debe incluir el resto del control de actividad: monitorización, alertas, informes, análisis forense y análisis de anomalías. Esto le ayudará a detectar los ataques que no pudo prevenir o que no anticipó.
- Estático Vs. Dinámico
- El Arte de la Reescritura SQL
- Lado de la Aplicación Vs. Lado de la BBDD
- Enmascaramiento Dinámico Vs. Bloqueo SQL
- Consideraciones Adicionales
- Tu Estrategia de 4 Pasos
Registrate al Webinar
Para saber más haz click aquí
Sugerencia de IA


¿Preguntas?
Si tenes alguna pregunta o comentario, no dude en hacérnoslo saber. Estaremos encantados de escucharles