Categoría: Article
-
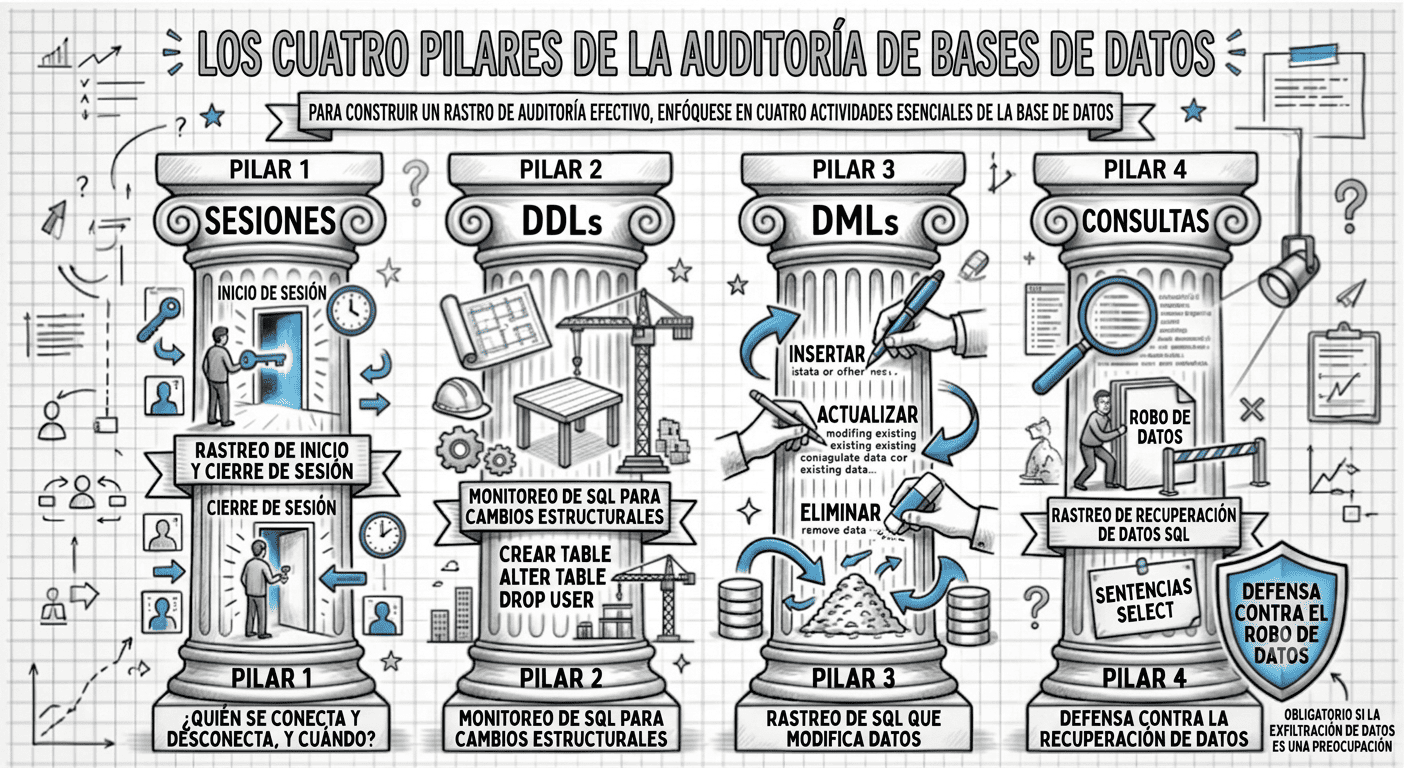
Hazlo Tú Mismo: Auditoría de Oracle GRATIS
Auditar una base de datos Oracle puede no ser una tarea sencilla, pero tampoco es demasiado difícil. Oracle incluye todo lo necesario de forma gratuita. Solo necesitas saber cómo integrar los componentes, y esta guía te mostrará el proceso, explicándote todo lo que necesitas saber. Los Cuatro Pilares de la Auditoría de Bases de Datos…
-
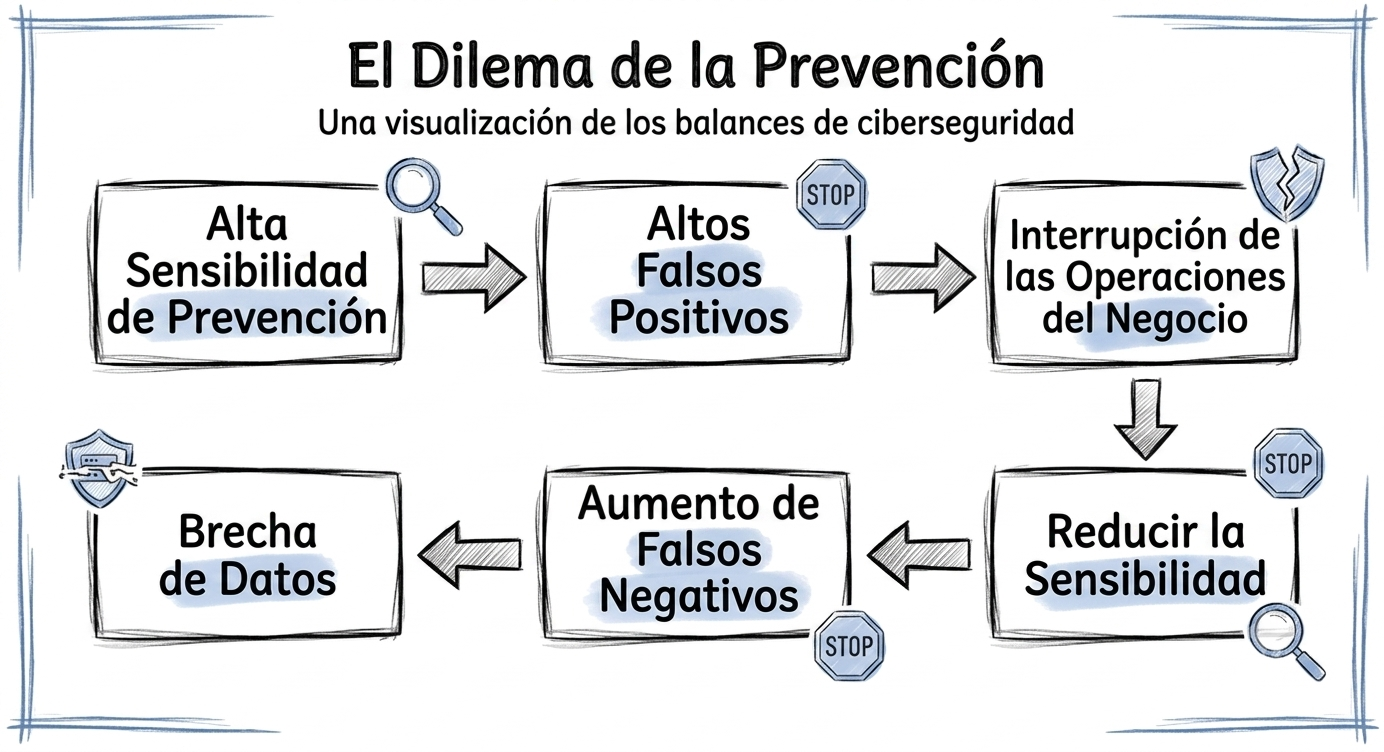
Cómo Proteger Tus Datos – Parte 1
La industria de la ciberseguridad se basa en un cúmulo de mentiras. Cada año, los equipos de seguridad empresarial invierten millones en firewalls de última generación, acceso a redes de confianza cero y proveedores de protección perimetral que prometen convertir su infraestructura en una fortaleza impenetrable. Cada año, surge una nueva promesa sobre la próxima…
-

Encuesta de Preferencias de Proveedores: El Proveedor Ideal
Recientemente, realizamos una encuesta entre un grupo de líderes en ciberseguridad y TI sobre su proveedor ideal de soluciones de seguridad de alta gama. Los resultados fueron contundentes: En teoría, esto tiene todo el sentido del mundo. Los líderes en seguridad son inteligentes y saben que los proveedores más pequeños y especializados son ágiles, se…
-

Análisis de la nueva Ley N° 21.719: El Nuevo Estándar de Protección de Datos en Chile
Con la llegada de la nueva Ley N° 21.719 de Protección de Datos Personales, cambian totalmente las formas en las que una organización debe gestionar, procesar y proteger la información personal de sus usuarios. Esta ley, que entrará en vigencia en diciembre de 2026, no es una simple actualización de políticas de privacidad, sino un…
-

¿Por Qué Falla la Seguridad de su Aplicación Java?
El ecosistema Java parece una fortaleza, y la seguridad es uno de sus puntos fuertes. Entre las especificaciones de Java, los robustos frameworks como Spring y un sinfín de bibliotecas de terceros, se construye sobre una base de seguridad prácticamente inexpugnable. Sin embargo, las filtraciones de datos no son una anomalía, sino algo habitual. Desde…
-

Una BBDD No Es Una Red: La Falacia de la Inspección de Paquetes.
La industria de la seguridad tiene la costumbre de intentar encajar piezas cuadradas en agujeros redondos. Uno de los ejemplos más recurrentes es el intento de proteger las bases de datos mediante tecnología centrada en la red. Se les denomina «cortafuegos de bases de datos» o sistemas de «monitorización de la actividad de bases de…
-
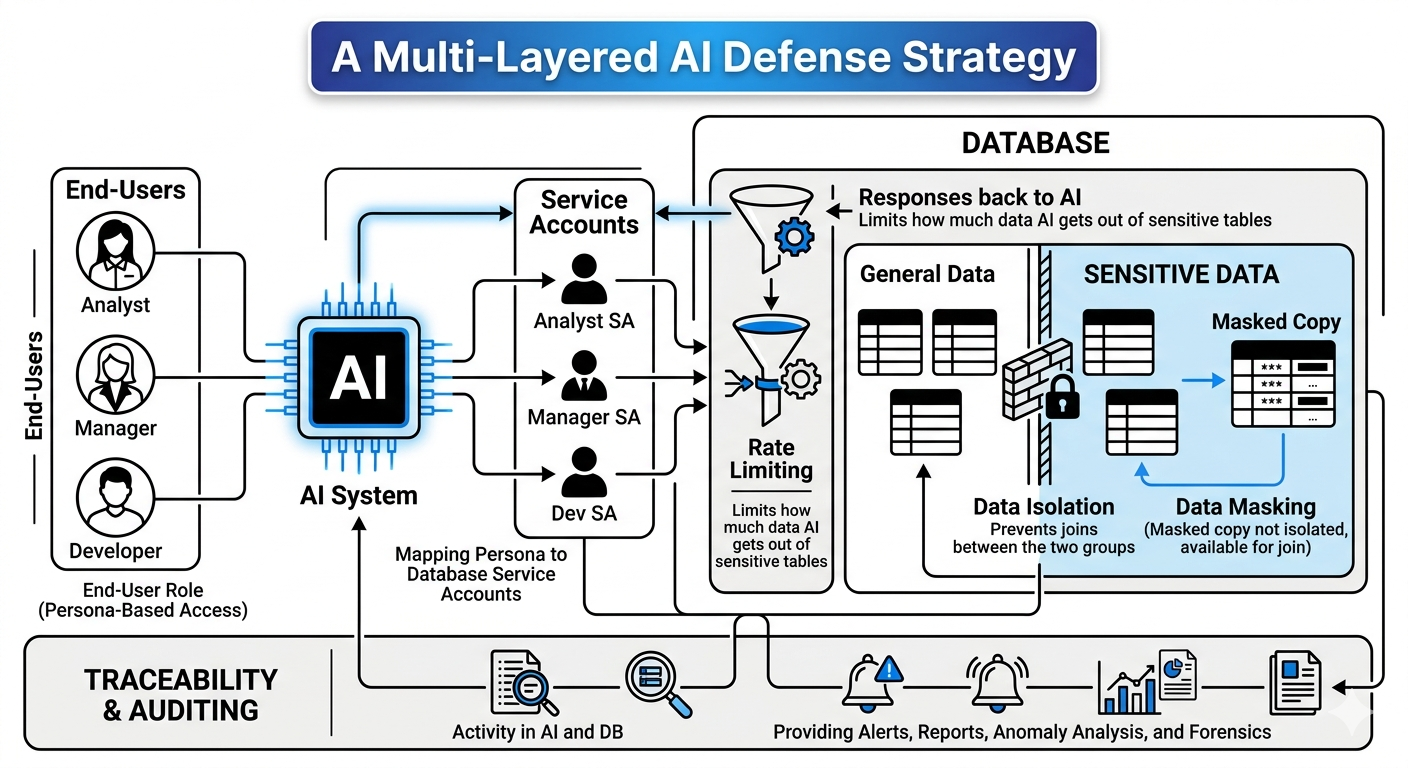
Seguridad de Datos en un Mundo de IA
La inteligencia artificial está transformando radicalmente nuestra interacción con la información. Si bien su potencial de productividad es enorme, introduce un cambio crítico en materia de seguridad para el que muchas organizaciones no están preparadas. En este artículo, nos centraremos en los desafíos específicos que surgen cuando las empresas implementan agentes de IA para fines…
-
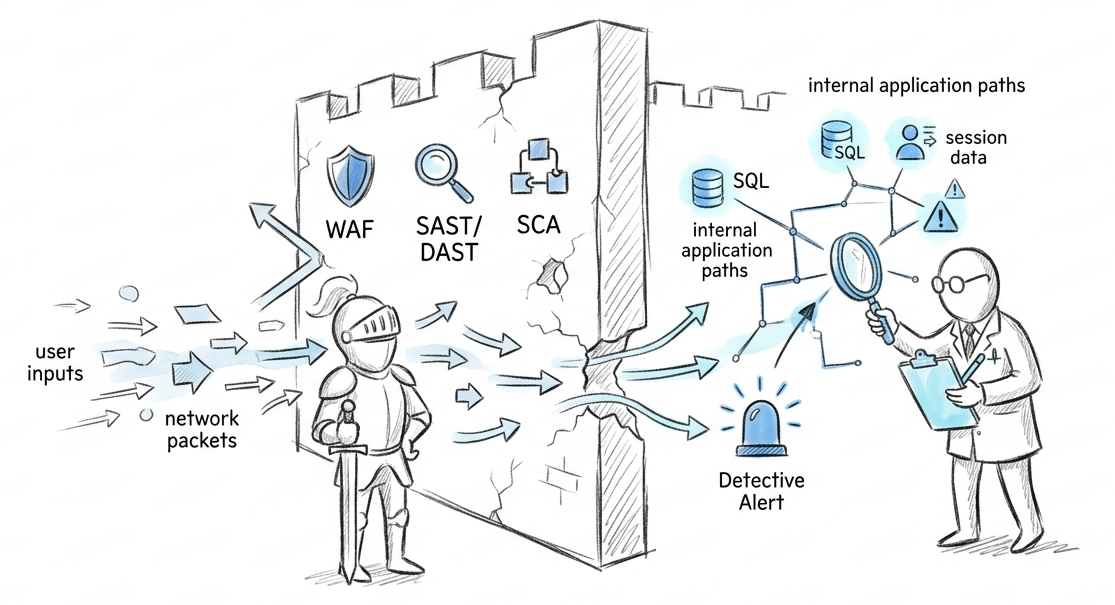
¿Por Qué Está Fallando la Seguridad de tu Aplicación?
Probablemente estés haciendo todo «bien», pero tu seguridad está fallando. Tu equipo sigue prácticas de desarrollo rigurosas. Utilizas Pruebas Estáticas de Seguridad de Aplicaciones (SAST) para auditar el código, Pruebas Dinámicas de Seguridad de Aplicaciones (DAST) para analizar tus entornos de ejecución, Análisis de Composición de Software (SCA) para gestionar tus bibliotecas y un Cortafuegos…
-

La Falsa Economía: Pagar un Precio Elevado por Soluciones Deficientes
En el mundo de IT, nos gusta creer que los datos objetivos y los resultados económicos son los que guían nuestras decisiones de compra. Sin embargo, en realidad, a menudo están influenciadas por un sesgo psicológico. Una encuesta reciente reveló que más del 90 % de los líderes de TI insatisfechos con sus soluciones actuales…
-
Enmascaramiento Dinámico de Datos: En la Aplicación, la Base de Datos y el Bloqueo SQL.
Analicemos algunas variantes del enmascaramiento dinámico de datos (DDM) y expliquemos las diferencias con su contraparte estática. Cubriremos diferentes enfoques de implementación, en qué situaciones se aplican y las alternativas preferidas. Estático vs. Dinámico: «Permanente» o «En Tiempo Real» Antes de profundizar en la implementación técnica, debemos distinguir entre las dos filosofías principales del enmascaramiento:…