Un cliente potencial nos confesó recientemente que estaba dudando entre comprar nuestra solución de enmascaramiento de datos o desarrollar una propia. Personalmente, suelo preferir desarrollar las cosas por mi cuenta. Sin embargo, como gerente de desarrollo y arquitecto de software con 30 años de experiencia, para el enmascaramiento de datos, mi recomendación es «comprar».
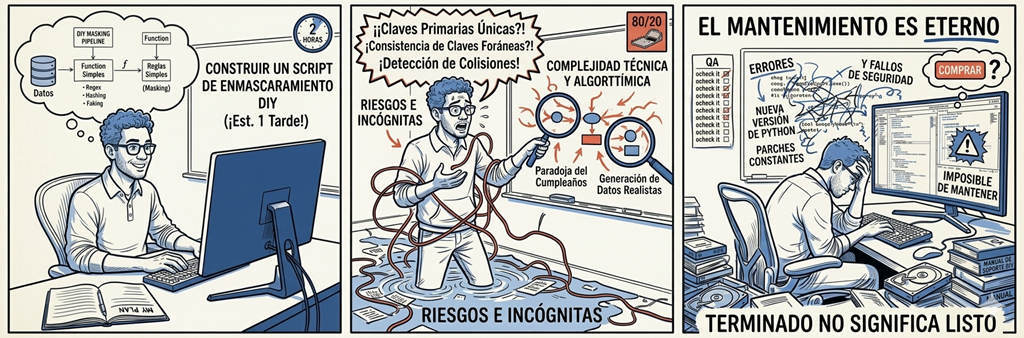
El enmascaramiento de datos puede ser complejo. Puede parecer un proyecto sencillo que se puede terminar en una tarde. Antes de que te lances a un proyecto de desarrollo, permíteme compartir algunas de mis experiencias en enmascaramiento de datos y otros proyectos. Esto podría ayudarte a evitar una inversión costosa sin retorno y a llegar a la misma decisión de compra. Explicaré por qué, cuándo deberías considerar desarrollar una solución propia y algunos de los obstáculos que tu equipo encontrará al intentarlo.
Y sí, hay casos en los que desarrollar una solución propia es una buena idea. Tenemos un artículo sobre Enmascaramiento de Datos DIY (hazlo tú mismo), que incluye scripts de ejemplo para empezar. Sin embargo, si tus requisitos van más allá de lo que pueden hacer esos scripts gratuitos, desarrollar una solución propia probablemente será un proceso largo y costoso.
La primera parte de este artículo analiza la perspectiva empresarial y de gestión de software, y la segunda se centra en la arquitectura del software y los detalles técnicos.
Alcance
Antes de abordar las consideraciones prácticas y técnicas, es importante definir claramente el alcance del proyecto. Una solución profesional que adquiera incluirá todo lo que espera de una solución de este tipo, como una interfaz de usuario, autenticación, registro de auditoría, etc. Además, se beneficiará de la percepción y la credibilidad de las que carece una solución desarrollada internamente.
Al considerar la opción de desarrollar internamente, probablemente no busque competir con una solución comercial, sino ahorrar costos utilizando recursos internos. Por lo tanto, debe tener en cuenta que el alcance de su proyecto dificultará la obtención de la aprobación de cumplimiento actual, por no hablar de la futura.
Sin embargo, es importante reconocer que siempre habrá deficiencias. Una solución comercial puede no cubrir el 100% de sus necesidades, al igual que una desarrollada internamente. La cuestión del alcance radica en cuál se acerca más a lo que necesita y cuán difícil o necesario es subsanar esas deficiencias. La razón por la que las soluciones comerciales de enmascaramiento parecen más atractivas es que sus deficiencias suelen ser menores.
Riesgos e Incógnitas
¿Cómo decidir entre desarrollar internamente o comprar? Puede parecer un simple ejercicio de sopesar pros y contras, pero al iniciar un proyecto de desarrollo, existen muchas incógnitas. El primer paso es, precisamente, comprender estas incógnitas y los riesgos que conllevan.
Creer que no existen incógnitas es una trampa peligrosa. Gestionar las incógnitas es parte fundamental de la gestión de software. Hasta que no se termina de desarrollar algo, no se pueden predecir todas las complejidades tecnológicas o algorítmicas, la gravedad o naturaleza de los errores, ni los desafíos de rendimiento y estabilidad que se avecinan. Diseñar un proyecto de software consiste en gestionar estos riesgos, no en preverlos.
Los desarrolladores suelen pensar que «es algo sin importancia» y que «lo terminaremos rápido». A veces es cierto. Pero otras veces es como meterse en un charco y darse cuenta de que es un agujero y que el agua te llega hasta el cuello. En un proyecto de enmascaramiento de datos, te das cuenta de que el agua es más profunda de lo esperado cuando empiezas a probarlo en la práctica. Es entonces cuando surgen los problemas de rendimiento y la falta de funcionalidades (véase más adelante en el artículo). Resulta difícil predecir la magnitud del problema, ya que depende del proyecto.
Gestión Empresarial y de Software
Gestionar un proyecto de software es un tanto complejo. Muchos gestores, incluyéndome, hemos cometido errores. En mi caso, al menos, el error suele ocurrir cuando me dejo llevar por la aparente complejidad del proyecto y subestimo principios fundamentales que conozco, como la regla del 80/20 y la importancia de evitar incógnitas. Recopilar requisitos sólidos y analizar todo detenidamente me ayuda a minimizar esos errores.
Economía de Escala
Hay una buena razón por la que la mayor parte del software del mundo es software comercial: el desarrollo de software solo es rentable cuando se cuenta con múltiples clientes que lo pagan. Al dividir los costos entre muchos clientes, la propuesta de valor para cada uno es mayor que el precio que paga. En esencia, se trata de 1000 clientes que contribuyen a la creación de una solución grande y completa.
Cuando la carga financiera total recae sobre un solo cliente, el valor de ese software debe ser único. Es muy difícil obtener suficiente valor cuando el 100 % del costo recae sobre uno mismo en lugar de distribuirlo entre 1000 o más empresas.
La Trampa del 80/20
La regla del 80/20 es una ley bien conocida en el desarrollo de software y se aplica a muchos ámbitos. Por ejemplo, el 20 % del esfuerzo se destina al 80 % de la funcionalidad, y el 80 % restante se utiliza para el 20 % restante. En general, la regla 80/20 significa que el tiempo, el esfuerzo y los costos que preveas serán probablemente cuatro veces mayores. Dependiendo del proyecto, esta regla podría convertirse en 90/10, 95/5 o, en casos extremos, el proyecto podría fracasar y no llegar a completarse. También implica cierta incertidumbre, ya que ese 20% suele ser parcialmente conocido y parcialmente oculto.
Puede parecer contradictorio, y muchas veces la gente responde con frases como «detente después del 80% y no termines el último 20%» o «Mi equipo experimentado puede predecir mejor el cronograma y los costos». Sí, es cierto. Un gerente de desarrollo experimentado podría tener en cuenta las incertidumbres y saber cómo reducir el alcance de las funcionalidades que requieren un esfuerzo desproporcionado. Sin embargo, ese gerente de desarrollo casi siempre te aconsejaría comprar una solución si ya existe una.
Hecho vs. Listo
Un error común es la diferencia entre «terminamos el desarrollo» y el momento en que los usuarios pueden empezar a usarlo. A veces, los gerentes de desarrollo se refieren a «funcionalidad completa» como el momento en que el producto está terminado. Sin embargo, es entonces cuando comienzan las pruebas y el largo proceso para que todo funcione correctamente.
Recuerdo perfectamente una conversación que tuve con mi experimentada jefa de proyecto cuando era un joven gerente de desarrollo. Yo pensaba que un proyecto debería durar entre uno y dos meses, pero ella fijó la fecha de entrega en seis meses. Me explicó que cuando yo decía que habíamos terminado de programar, era cuando empezábamos con el control de calidad. Con dos rondas de control de calidad, las correspondientes rondas de corrección de errores y las listas de verificación de aceptación, seis meses era un plazo realista.
En ese momento, me pareció mucho tiempo perdido y estaba seguro de que podíamos terminar antes. Resultó que mi experimentada jefa de proyecto sabía exactamente lo que hacía, y entregamos el producto a tiempo, justo cuando ella lo había previsto.
Así que, cuando recibas estimaciones, investiga a fondo. Intenta comprender los entregables, qué faltará y si se tratará de una prueba de producción o simplemente de una funcionalidad completa. La diferencia puede ser de cientos de puntos porcentuales.
Las Soluciones Más Sencillas
Otra interpretación del principio 80/20 es que el 80 % de la funcionalidad requiere el 20 % del esfuerzo, y el 20 % restante consume la mayor parte del tiempo. En el enmascaramiento de datos, por ejemplo, convertir caracteres en otros caracteres o en asteriscos es sencillo. Hay muchas cosas simples que se pueden hacer con un script de una sola línea.
Sin embargo, algunas cosas son increíblemente difíciles de lograr, y si necesitas alguna de ellas, no deberías considerarla para un proyecto propio. Un buen ejemplo es la unicidad y la consistencia: asegurarse de que las claves primarias enmascaradas sean únicas y que las claves foráneas apunten a esos valores.
Si inicias un proyecto de enmascaramiento, no ignores esos requisitos pequeños pero difíciles. Sin ellos, tu proyecto es inútil, y lograrlos puede ser una tarea monumental.
Mantenimiento
En el desarrollo de software, una de las primeras cosas que los gerentes olvidan es el mantenimiento. Resulta curioso, porque es la razón por la que se pagan cuotas anuales de mantenimiento a los proveedores de software. Al fin y al cabo, se necesitan actualizaciones de seguridad periódicas, correcciones de errores y soporte técnico cuando algo falla.
Según la teoría de la ingeniería de software, el 20 % del tiempo se dedica a escribir el código y el 80 % a mantenerlo. Estas proporciones se utilizan para explicar por qué vale la pena invertir en el desarrollo de software de calidad (reduce la carga de mantenimiento posterior). Para la mayoría del software, esta cifra se queda corta, y la realidad suele ser 90/10.
Como se puede observar en cualquier software que se utilice, siempre hay parches y nuevas versiones, y nunca llega a un estado «terminado». Es como adoptar una mascota: hay que alimentarla y cuidarla constantemente. ¿Pero por qué? Hay muchas razones, desde errores y fallos de seguridad hasta requisitos cambiantes, entre otras. Sin mencionar la evolución natural del conjunto de tecnologías con nuevas versiones de PHP, Python, Java, jQuery, .NET, sistemas operativos, etc. Es una realidad innegable que, mientras uses el software, tendrás que seguir invirtiendo en él.
¿Cuándo Desarrollar Internamente?
Existen varios escenarios conocidos en los que desarrollar internamente es mejor que comprar. La mayoría no se aplican al enmascaramiento de datos, pero vale la pena revisarlos de todos modos:
- Los requisitos básicos pueden sugerir que considere desarrollar usted mismo el enmascaramiento de datos. Si un script puede hacer lo que necesita, no es necesario comprar una solución. En nuestro artículo sobre enmascaramiento de datos «hágalo usted mismo», ofrecemos ejemplos de enmascaramiento que puede realizar utilizando recursos internos. Si estos scripts cumplen con sus necesidades, no hay razón para comprar. Sin embargo, si existe una brecha de funcionalidad entre ellos y sus requisitos, debería comprar.
- La funcionalidad única es la razón más común para los proyectos de desarrollo interno completos. Si ningún producto puede hacer lo que necesita, no tiene otra opción. Si requiere la funcionalidad, debe pagar por el desarrollo. Puede ser costoso, pero es el costo de operar un negocio.
- Personalización significativa. Cuando existe una solución disponible para la compra, pero requiere una inversión significativa para adaptarla a sus requisitos. Sin embargo, la mayoría de los ejemplos, desde sistemas ERP hasta sistemas de gestión de incidencias, demuestran que incluso con personalizaciones extensas, es más económico comprar y personalizar que desarrollar desde cero.
- Software gratuito/de código abierto. Desafortunadamente, no existe una solución de enmascaramiento empresarial completa y gratuita. Pero incluso si existieran, los proyectos de código abierto requieren un esfuerzo considerablemente mayor para su implementación y soporte. Por eso IBM adquirió Red Hat por 34 mil millones de dólares. El modelo de negocio de Red Hat se basa en convertir software libre en algo que las empresas estén dispuestas a implementar.
- Control y dependencia. Cuando el software es fundamental para el negocio, una organización puede optar por desarrollarlo internamente para mantener el control sobre el código y las estructuras de datos, y eliminar la dependencia de proveedores externos. Esto también ayuda a mantener un elemento diferenciador y una ventaja competitiva. Por ejemplo, un banco puede optar por desarrollar su propio software bancario en lugar de comprar y personalizar una aplicación de gestión bancaria estándar. Sin embargo, el enmascaramiento de datos no forma parte de su actividad principal.
En resumen, al igual que no se construiría un sistema de gestión de incidencias o un sistema de control de versiones, tampoco se debería construir una solución de enmascaramiento de datos.
Riesgos de la Construcción
Existen tres riesgos principales en cualquier proyecto de construcción: tiempo, costes y entregables.
Cuando se compra, se sabe qué se obtiene, cuándo se obtiene y cuánto cuesta. No hay incógnitas. Y el plazo, en concreto, es muy corto.
Cuando se construye, el plazo siempre será más largo, pero además de la espera, también se corre el riesgo de que el proyecto se prolongue aún más. Esto es extremadamente común, por lo que es una expectativa realista que se debe tener en cuenta. Cuando un proyecto se prolonga, el pago de salarios implica que también se está excediendo el presupuesto. Esto también es muy común y algo que se debe prever.
Por último, los proyectos tienden a reducir el alcance de la funcionalidad cuando el tiempo es un factor crítico. Dependiendo de la funcionalidad que se reduzca, puede ser una solución aceptable o hacer que la solución sea inservible. Debe tener en cuenta que algunas de las funcionalidades críticas que necesita pueden quedar fuera del alcance del proyecto debido a limitaciones de tiempo o complejidad técnica.
Soporte del Proveedor
El enmascaramiento de datos presenta innumerables dificultades. Se trata de manipular datos de producción y encontrar el equilibrio entre seguridad y utilidad. Por un lado, existen estrictos requisitos de seguridad y cumplimiento normativo. Por otro, los equipos de desarrollo y control de calidad deben encontrar útiles los datos enmascarados.
Más allá del desafío algorítmico, también existe el desafío técnico de implementarlo. Si surgen problemas, por ejemplo, debido a disparadores, necesitará personal con experiencia que sepa cómo solucionarlos.
Una de las razones fundamentales para invertir en una solución de enmascaramiento es que incluye soporte. Asegúrese de trabajar con un proveedor que garantice el éxito de su proyecto y no le falle.
Arquitectura de Software
Crear una solución de enmascaramiento de datos parece muy sencillo. Se leen los datos, se aplica un algoritmo simple y se vuelven a escribir enmascarados. ¿Qué podría salir mal?
Contrariamente a esta primera impresión, el enmascaramiento estático de datos presenta algunos desafíos. Uno de ellos es el mecanismo técnico de lectura y escritura, y los demás se relacionan con los algoritmos de enmascaramiento que aplicamos.
Rendimiento de Escritura
Leer los datos es bastante sencillo, pero escribirlos es un desafío. Es difícil porque actualizar un millón de filas requiere un millón de actualizaciones, y tantas actualizaciones pueden tardar días o semanas en completarse.
Existen 3 arquitecturas posibles para construir una solución de enmascaramiento de datos, cada una con su propio conjunto de inconvenientes:
- Solución externa: Software independiente que se conecta a la base de datos y envía sentencias SQL (SELECT y UPDATE). El problema radica en que las latencias de milisegundos en las ejecuciones SQL se acumulan hasta generar tiempos de ejecución totales excesivamente largos.
- Actualizaciones verticales: Una única sentencia SQL que actualiza todas las filas de la tabla. Esta es una solución elegante para el problema de las múltiples actualizaciones, pero plantea otro desafío en cuanto a la funcionalidad.
- Solución interna: Software que se ejecuta dentro del motor de la base de datos, escrito, por ejemplo, en PL/SQL en Oracle o TSQL en SQL Server. Este método intenta superar el problema de la latencia, pero genera un desafío de rendimiento insuperable.
En esta explicación, usaré algunos ejemplos y terminología del entorno Oracle, pero existen ejemplos y terminología equivalentes en cualquier base de datos.
En última instancia, las soluciones reales de enmascaramiento de datos siempre se ejecutan como software externo. La razón es que es la única forma de ejecutar algoritmos de enmascaramiento adecuados. Sin embargo, la latencia es un gran inconveniente.
Si observa un tiempo de ping de 10 ms, significa que el tiempo de red por sí solo no le permitirá ejecutar más de 100 actualizaciones por segundo. Incluso con un ping de 1 ms, hay que tener en cuenta el tiempo que tarda la base de datos en recibir la consulta SQL y ejecutarla. Con 100 actualizaciones por segundo, se tardarían 2 horas y 45 minutos en ejecutar un millón de actualizaciones. Si tiene 20 columnas para actualizar, estaríamos hablando de más de 2 días. De hecho, esto es optimista, y podría terminar con una semana para ejecutar el enmascaramiento.
Pero hay una solución: el enlace de matrices. Una sentencia preparada se puede enviar no solo con un único conjunto de variables de enlace, sino con una matriz de ellas. Enviar un array de variables de enlace para su ejecución significa que, en una sola comunicación, se pueden ejecutar miles de consultas SQL, eliminando así la latencia.
También es importante cómo se accede a las filas. El uso de localizadores de bloques, como los ROWID, permite que las actualizaciones se ejecuten con extrema rapidez. Existen otros trucos, como realizar confirmaciones periódicamente para evitar transacciones largas, etc.
Si bien todo esto es factible, no se trata de código de base de datos trivial y requiere experiencia, experimentación y pruebas suficientes para implementarlo correctamente. Sin embargo, una solución bien programada puede ejecutar casi cualquier lógica de enmascaramiento y actualizar un millón de filas en 9 segundos.
Para evitar problemas como la latencia y el direccionamiento de filas, se puede usar una actualización vertical. Una actualización vertical es una única instrucción UPDATE que modifica varias filas o, en este caso, todas las filas de la tabla.
El desafío de una actualización vertical radica en que la transformación debe usar funciones integradas de la base de datos. Por ejemplo, usar una función TRANSLATE en una instrucción UPDATE de Oracle con algunas operaciones DBMS_RANDOM puede procesar un millón de filas en aproximadamente 54 segundos. Es mucho más lento que el software externo, pero aún dentro de un rango aceptable. El desafío es que las transformaciones más complejas tardarán exponencialmente más.
Sin embargo, crear una solución interna es mucho peor. Escribir una función PL/SQL con un bucle que itere a través de la cadena (con la misma lógica TRANSLATE) aumenta el tiempo a 9 minutos. Implementarlo en un procedimiento almacenado PL/SQL en lugar de una función produce resultados similares de 9 minutos. Si bien una solución interna no está limitada por las funciones integradas de la base de datos, el código PL/SQL complejo puede tardar muchísimo en ejecutarse.
Si tomamos la solución externa como referencia, estas son las implicaciones de rendimiento en la prueba que realizamos en una instancia específica de Oracle:
| Método | Tiempo | % Tiempo | Notas |
|---|---|---|---|
| Solución Externa (Referencia) | 9 segundos | 100% | Software de externo bien programado |
| Actualización Vertical | 54 segundos | 600% | Mediante TRANSLATE |
| Solución interna (SQL Function) | 9 minutos | 6.000% | Bucle simple sobre una cadena corta |
| Solución interna (Stored Procedure) | 9 minutos | 6.000% | Bucle simple sobre una cadena corta |
Tenga en cuenta que estas pruebas de rendimiento se realizaron en una instalación específica de Oracle con una configuración particular. Otras bases de datos Oracle, por no hablar de otros tipos de bases de datos como SQL Server, arrojarán resultados muy diferentes. Le sugiero que realice sus propias pruebas de rendimiento en el tipo de entornos que planea enmascarar.
Sin embargo, el concepto general se mantiene:
- Si se puede solucionar el problema de latencia, ejecutar la lógica de enmascaramiento fuera de la base de datos es la opción más rápida.
- Usar una actualización vertical que dependa de las funciones integradas de la base de datos es más lento, pero funciona bien para un proyecto sencillo de bricolaje. Ofrece una funcionalidad limitada, lo cual puede ser aceptable.
- Usar software interno programado en el lenguaje de scripting de la base de datos (ya sea como función o procedimiento) es increíblemente lento, y una lógica compleja lo hará inviable.
De nuevo, a medida que la lógica de enmascaramiento se vuelve más compleja, la actualización vertical y la solución interna se convierten en vías inaceptables.
Algoritmos de Enmascaramiento
Un proyecto de bricolaje está limitado por el tipo de algoritmos de enmascaramiento que puede implementar. Si bien no se necesitan algoritmos complejos para todos los campos, sí son necesarios incluso si solo se requieren para uno.
Aquí hay algunos ejemplos de algoritmos complejos:
Unicidad / Clave Primaria: Si uno de los campos que requiere enmascaramiento debe ser único, funcionar como clave primaria o tener un índice único, la generación de valores debe incluir detección de colisiones y re-enmascaramiento. En otras palabras, cuando se enmascara una columna única, el proceso debe garantizar que el mismo valor enmascarado no se repita. Un «valor grande» probablemente no ayude debido a la paradoja del cumpleaños.
| Longitud de la Llave | 99% de probabilidad de colisión |
|---|---|
| 8 dígitos | 30,000 filas |
| 9 dígitos | 100,000 filas |
| 10 dígitos | 300,000 filas |
| 11 dígitos | 1,000,000 filas |
| 12 dígitos | 3,000,000 filas |
Enmascarar un número de seguridad social (9 dígitos) prácticamente garantiza una colisión en 100 000 filas, y cambiar aleatoriamente un número de teléfono (10 dígitos) generará un duplicado en 300 000 filas.
Para garantizar la unicidad, una solución debe mantener su propio algoritmo de detección de colisiones de valores o depender de la base de datos para detectar duplicados y volver a enmascarar si hay un error.
Consistencia / Clave foránea: Para garantizar la integridad referencial, ciertos valores deben enmascararse de la misma manera en diferentes columnas y, potencialmente, en diferentes bases de datos.
La única forma de hacerlo correctamente es usar un diccionario de enmascaramiento que mapee los valores originales a los valores enmascarados. Este diccionario debe consultarse para cada valor antes de aplicar el algoritmo de enmascaramiento.
Existe una alternativa común, aunque defectuosa, que consiste en depender del enmascaramiento determinista. Esta alternativa falla cuando el valor enmascarado previsto colisiona con la clave primaria y requiere un nuevo enmascaramiento. En ese caso, la referencia de la clave foránea no conocería el valor alternativo utilizado en la clave primaria.
Generación de datos: En muchos casos, es necesario generar datos textuales realistas. Por ejemplo, nombres, apellidos, nombres completos, direcciones de correo electrónico, direcciones postales, etc. La generación de datos se basa en diccionarios de nombres y patrones utilizados para combinarlos (generalmente con ponderaciones que determinan la frecuencia de cada patrón).
Conjuntos de datos limitados: Algunas columnas pueden tener un número limitado de valores válidos. Por ejemplo, el género (masculino o femenino), el nombre del país, el código postal, etc. Si bien es posible enmascarar conjuntos de datos limitados incluso con actualizaciones verticales, el rendimiento suele ser muy deficiente para tablas grandes. Aplicar ponderaciones para garantizar que los datos enmascarados cumplan ciertas proporciones complica mucho más este proceso.
Compuestos: En algunos casos, es necesario enmascarar varias columnas simultáneamente. Por ejemplo, la ciudad, el estado y el código postal. Al enmascararlos juntos, los datos enmascarados pueden conservar las relaciones entre las columnas. Si la aplicación requiere que los datos enmascarados preserven dichas relaciones (por ejemplo, garantizar que un código postal coincida con la ciudad y el estado), esto es fundamental.
Análisis de patrones: En ciertos casos, es recomendable analizar los datos originales para que los datos enmascarados generados sean similares. Por ejemplo, para determinar los patrones de tarjetas de crédito o números de teléfono presentes en los datos originales, así como su frecuencia.
Fechas como cadenas de texto: Algunos conjuntos de datos almacenan información de fecha y hora como cadenas de texto. En estos casos, los datos textuales deben convertirse a algún formato interno de fecha/hora, enmascararse y, posteriormente, volver a convertirlos al formato original.
LOBs: En algunos conjuntos de datos, la información confidencial se almacena en formato binario. Las imágenes, las huellas dactilares y otros datos biométricos son ejemplos perfectos. Este tipo de datos suele almacenarse como LOBs (objetos grandes), imágenes, datos binarios, etc.
Reflexión Final
Al tener en cuenta los costos de desarrollo, pruebas, mantenimiento y soporte, el enfoque «hágalo usted mismo» (DIY) resulta mucho más caro de lo que parece inicialmente. Si a esto le sumamos la incertidumbre en los plazos de entrega, los riesgos y las limitaciones de capacidad, se vuelve aún menos atractivo. Un proyecto de enmascaramiento DIY solo es viable si se trata de un script sencillo que se pueda implementar en cuestión de horas o días. Algo que se pueda descartar fácilmente si se necesita más. Un plazo mayor probablemente resultará en un proyecto fallido que, de todos modos, requerirá la compra de una solución.
Analice algunos de los detalles de este artículo y compárelos con el responsable del proyecto:
- ¿Disponen de una lista de requisitos que asocie todos los datos que necesita enmascarar?
- ¿Cuál es el plazo para que entreguen una solución probada y lista para producción que cumpla con dichos requisitos?
- ¿Han evaluado el rendimiento de la arquitectura propuesta?
- ¿Ha tenido en cuenta el mantenimiento a largo plazo, el soporte y la evolución de los requisitos futuros?
El coste del desarrollo interno nunca es rentable cuando existen soluciones comerciales que satisfacen tus necesidades. De lo contrario, esas soluciones no existirían y todos optarían por el desarrollo interno. Tarde o temprano, los desarrollos internos se topan con un límite de complejidad o de mantenimiento, y resulta más económico asumir las pérdidas y comprar una licencia. Si ese es el escenario más probable, quizás sea más fácil evitar la fase de desarrollo propio.
La pregunta clave podría ser: «¿Merece la pena?». ¿No sería mejor invertir esos recursos y el quebradero de cabeza que supone una solución que podrías comprar en tu negocio principal?
- Introducción
- Alcance
- Riesgos e Incógnitas
- Gestión Empresarial y de Software
- Arquitectura de Software
- Reflexión Final
Sugerencia de IA


¿Preguntas?
Si tenes alguna pregunta o comentario, no dude en hacérnoslo saber. Estaremos encantados de escucharles