Categoría: Article
-

¿Por Qué No Coinciden Los Presupuestos y Los Intereses en Seguridad?
Recientemente realizamos dos encuestas globales para conocer la situación del sector de la ciberseguridad. La primera planteaba una pregunta sencilla: «¿Qué temas le interesan?». La segunda preguntaba: «¿Dónde se están desarrollando sus proyectos este año?». Los resultados revelaron una sorprendente desconexión entre dónde se invierte el dinero y qué preocupa realmente a los profesionales. Al…
-
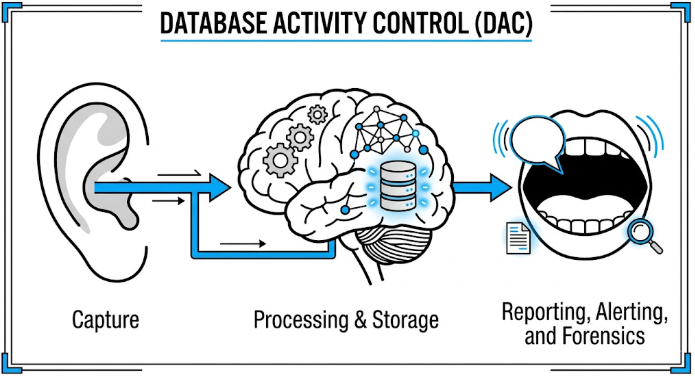
Las Mejores Soluciones de Control de Actividad de Bases de Datos
La monitorización de la actividad de la base de datos (DAM) o su variante moderna, el control de la actividad de la base de datos (DAC), tiene como objetivo mejorar la seguridad de las bases de datos y lograr el cumplimiento normativo. Dado que la mayoría de los usuarios de bases de datos tienen acceso…
-
Enmascaramiento de Datos Estático: ¿Desarrollar Internamente o Comprar?
Un cliente potencial nos confesó recientemente que estaba dudando entre comprar nuestra solución de enmascaramiento de datos o desarrollar una propia. Personalmente, suelo preferir desarrollar las cosas por mi cuenta. Sin embargo, como gerente de desarrollo y arquitecto de software con 30 años de experiencia, para el enmascaramiento de datos, mi recomendación es «comprar». El…
-

Guía Completa Para Enmascaramiento de Datos Estático
El enmascaramiento estático de datos (SDM) consiste en reemplazar información confidencial con datos realistas, pero ficticios, en entornos no productivos. El objetivo es simple: eliminar el riesgo de seguridad. Dado que las bases de datos están diseñadas para manipular datos a escala, puede optar por aprovechar estas capacidades y optar por un enfoque «hágalo usted…
-
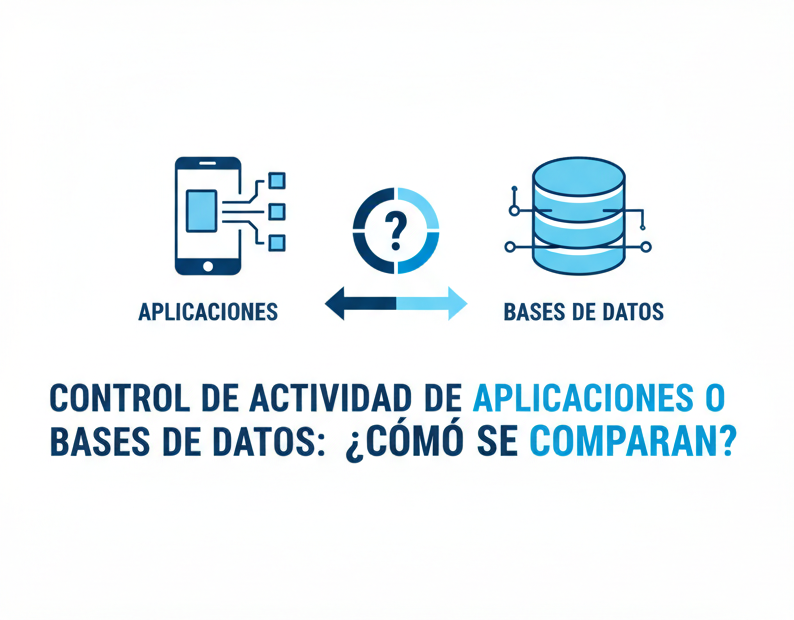
Control de Actividad de Aplicaciones o Bases de Datos: ¿Cómo se Comparan?
Todos los ataques tienen el mismo destino: los datos de la base de datos. Sin embargo, el 99 % de la actividad de la base de datos se origina en una única cuenta de servicio de la aplicación. Entonces, ¿cómo se compara el control de la actividad de la base de datos con el control…
-
Tecnología de Seguridad de Bases de Datos: No Te Quedes Atrás
Invertimos millones en firewalls y EDR para proteger el perímetro y los endpoints. Pero el verdadero valor, sus datos, a menudo reside en una bóveda protegida por un candado de 25 años. Nuestra información es lo que buscan los atacantes, pero es lo que menos protegemos. En una casa hecha de puertas, nos obsesionamos con…
-

Encuentra Datos Confidenciales de Forma Gratuita Utilizando IA
El Desafío¿Qué Datos Tengo? La mayoría de las organizaciones se enfrentan a un obstáculo crítico de cumplimiento y seguridad: en realidad no saben dónde viven sus datos confidenciales. Sin embargo, con la llegada de la IA, ahora puede escanear fácilmente un esquema de base de datos completo en unos pocos minutos o menos. El obstáculo…
-

Pautas de Gasto en Seguridad de Bases de Datos
Encontrar el nivel de inversión «correcto» para la seguridad de bases de datos no es sencillo. A diferencia de los antivirus, no se trata de una simple comparación entre varios proveedores. Los modelos de precios no coinciden y las características son mucho más complejas e imposibles de comparar. Para colmo, rara vez sabemos exactamente lo…
-

Enmascaramiento: El Límite de Velocidad
¿Su enmascaramiento de datos estáticos tarda días cuando debería tardar minutos? En el mundo ágil con plazos de entrega rápidos, este es un problema que paraliza el desarrollo y es más común de lo que la mayoría de las organizaciones admiten. Muchas empresas terminan con software de almacenamiento: soluciones de enmascaramiento costosas que no se…
-

Checklist Para la Evaluación de Bases de Datos
Las organizaciones dependen de los datos, y las bases de datos son el lugar donde se almacenan dichos datos. Las bases de datos son el corazón que bombea estos datos por toda la organización, manteniéndolos vivos. Pero a medida que los volúmenes de datos se disparan y las regulaciones se endurecen, tratar la seguridad de…